1 Introduction
Researchers make millions of protons collide every second inside the Large Hadron Collider (LHC) deep below the French-Swiss border near Geneva to understand what our universe is ultimately made of. Each collision creates subatomic particles which often decay quickly, creating even more particles. Sensors surround the collision zone and record the passage of these particles, turning each collision event into data – a lot of data. CERN, the European Organization for Nuclear Research, is the world’s largest particle physics laboratory. CERN’s data center processes up to a petabyte of data per day. That’s a million gigabytes. These amounts of data are far beyond anything a human can look at.
To call the analysis of this data “challenging” is a complete understatement: It’s difficult to reconstruct the collisions because multiple collisions occur simultaneously; sensor data is generated faster than it can be written to disk; and some particles decay in less than a trillionth of a trillionth of a second. To make the data processing and analysis manageable, CERN researchers rely on machine learning. Machine learning systems scan the incoming event data and decide which to write to disk and which to ignore. Machine learning models also estimate the energy and timing of signals. Other machine learning models help reconstruct events and remove noise. Today, particle science at CERN is unthinkable without machine learning.
But it’s not just particle science. If you look closely, you’ll find machine learning in almost every field (at least, we couldn’t find any without it). There are fields where everyone expects machine learning applications, such as geoscience, materials science, or neuroscience [1], [2], [3]. But you might be surprised to see machine learning applied in other fields, such as anthropology, history, or theoretical physics [4], [5], [6].
Let’s look at a few applications to get a better sense of how scientists use machine learning. In each example, machine learning plays a different scientific role.
Raven Science was stuck. The Ravens were drowning in complex data and had no idea how to compress it into a scientific model. A peculiar bunch of neuro-stats-computer Ravens had recently developed a new modeling approach called supervised machine learning, which learns predictive models directly from data. But is this kind of modeling still science, or is it alchemy?
1.1 Labeling wildlife in the Serengeti
Wildlife ecologists want to understand and control the complexities of natural ecosystems. They ask questions like: What animals live in the ecosystem? How many animals of each species are there? What do the animals do?
For a long time, it was difficult to analyze these questions quantitatively because there was simply no data. But today, motion sensor cameras, often referred to as camera traps, make huge amounts of data available. Camera traps combine cameras with motion sensors. Once something moves in front of the camera, it takes pictures. The Serengeti, home to zebras, buffalos, and lions, is one of the ecosystems where ecologists placed various camera traps. But to turn these images into insights, people had to label them: they had to decide whether an animal was in the picture, what species it belonged to, and describe what it was doing. A tedious task!
For this reason, Norouzzadeh et al. [7] used the already labeled data to train a convolutional neural network that performs this task automatically. Figure 1.1 shows the output of this labeling task. The model achieves a prediction performance of 94.9% accuracy on the Snapshot Serengeti dataset – the same performance as crowdsourced teams of volunteers who typically label the data.

The primary goal of the paper is to provide a reliable labeling tool for researchers. The labels for the data should be accurate enough to draw scientific conclusions. Therefore, Noroyzzadeh et al. [7] are concerned with the predictive accuracy of the model under changing natural conditions and the uncertainty associated with the predictions.
1.2 Forecasting tornadoes to inform actions
In the case of severe weather events like tornadoes, every minute counts. You need to find shelter for yourself and your loved ones quickly. But tornadoes are hard to predict. They form rapidly and the exact conditions for a tornado to form are not fully understood.
Lagerquist et al. [8] therefore use machine learning to predict the occurrence of a tornado within the next hour. They trained a convolutional neural network on data from two different sources: storm-centered radar images and short-range soundings. Their model achieves similar performance to ProbSevere, an advanced machine learning system for severe weather forecasting that is already in operation.
The work aims to provide a system that could be used in deployment to help warn the population of tornadoes. Therefore, the paper centers on the methodology and the assessment of the model’s predictive performance in relevant deployment settings. In particular, they analyzed in which regions the model worked best and worst in terms of prediction error for different types of tornadoes. The use case differs from the Serengeti animal classifier where the goal was labeling, not case-by-case decision-making (although summary data from Serengeti might end up for decision-making).
1.3 Predicting almond yield to gain insights
California is the almond producer of the world: it produces 80% of all the almonds on Earth, probably in the entire Universe. Nitrogen, a fertilizer, plays a key role in growing the nuts.1 Fertiliser is regulated, meaning there’s an upper limit for its use. Before you can develop a good fertilizer strategy, you have to quantify its effect first. Zhang et al. [9] used machine learning to predict the almond yield of orchard fields, based on weather, orchard characteristics using remote sensing (satellites), and, of course, fertilizer use. The authors examined the model not only for its predictive accuracy but also for how individual features affect the prediction and how important they are for the model’s performance.
The goal of this research is twofold: prediction and insight, so it goes beyond just making a decision. The model may help almond growers make better decisions about fertilizer use but also contribute to the scientific knowledge base. In general, the scientific fields of ecology and agriculture are at the forefront when it comes to adapting machine learning [10], [11].
1.4 Inferring protein structures for scientific hypotheses
One of the big goals in bioinformatics is to understand how protein structures are determined by their amino acid sequences. Proteins do a lot of heavy lifting in the body, from building muscles and repairing the body to breaking down food and sending messages. A protein’s structure is largely determined by its sequence of amino acids, the building blocks of protein. The protein’s structure, however, ultimately determines its function. The problem: It is difficult to predict how a protein will be structured if you only have the amino acid sequence. If scientists could do that reliably, it would help them with drug discovery, understanding disease mechanisms, and designing new proteins. Meet AlphaFold [12], a deep neural network that can predict protein structures from their amino acid sequence reasonably well. See Figure 1.2 for one example.
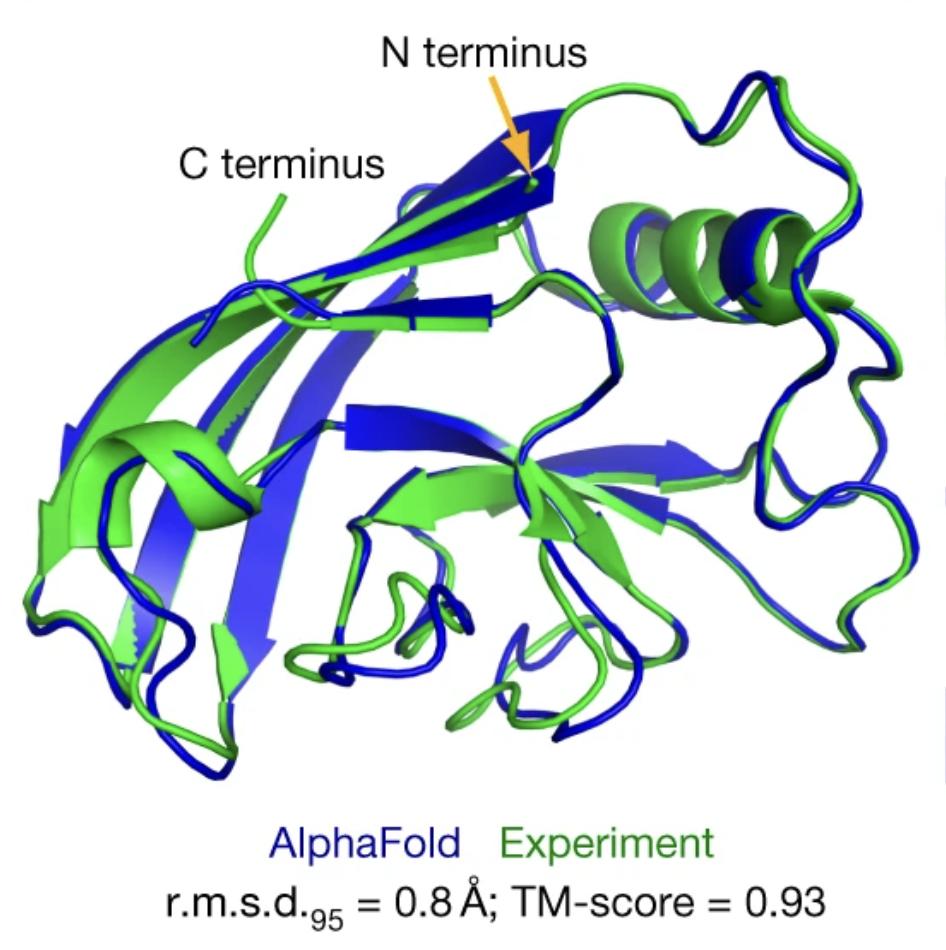
AlphaFold was trained on a dataset of 100,000 protein sequences. Beyond pure prediction, the algorithm aids with molecular replacement [13] and interpreting images of proteins taken with special microscopes [14]. There’s now even an entire database, called AlphaFold DB, which stores the predicted protein structures. On its website [15] it says:
“AlphaFold DB provides open access to over 200 million protein structure predictions to accelerate scientific research.”
Not only has the prediction model AlphaFold become part of science, but its predictions serve as a building block for further research. To justify this sensitive role of machine learning, the model needs to be doubly scrutinized.
1.5 What role does machine learning play in science?
You may look at these examples and argue that machine learning is only one of many tools in the scientific process, like Excel or Python, or that the scientific goal was only to evaluate the model’s performance.
If this were the case, the value of machine learning in science would be very limited – machine learning could create ‘models’, but these bear little resemblance to scientific models that represent phenomena. The most important methodological steps in science – such as creating scientific models or theories, testing them, and finding interesting new research problems – would remain unaffected by machine learning.
Indeed, there are good reasons why everyone is cautious about machine learning in science – in its raw form, machine learning reduces every scientific question to a prediction problem. This restraint is emphasized by popular critical voices about machine learning.
Take Judea Pearl, a proponent of causal inference, who said that
“I view machine learning as a tool to get us from data to probabilities. But then we still have to make two extra steps to go from probabilities into real understanding — two big steps. One is to predict the effect of actions, and the second is counterfactual imagination.” [16]
Pearl refers here to his ladder of causation that distinguishes three ranks: 1. association, 2. intervention, and 3. counterfactual reasoning [17]. He highlights that machine learning remains on rank one of this ladder and is only suitable for static prediction.
Gary Marcus, one of the most well-known critics of current deep learning claimed that
“In my judgement, we are unlikely to resolve any of our greatest immediate concerns about AI if we don’t change course. The current paradigm – long on data, but short on knowledge, reasoning and cognitive models – simply isn’t getting us to AI we can trust.” [18]
In the paper, Marcus criticizes the lack of robustness, the ignorance of background knowledge, and the opacity in the current machine learning approach.
Noam Chomsky, one of the founding fathers of modern linguistics argued:
“Perversely, some machine learning enthusiasts seem to be proud that their creations can generate correct “scientific” predictions (say, about the motion of physical bodies) without making use of explanations (involving, say, Newton’s laws of motion and universal gravitation). But this kind of prediction, even when successful, is pseudoscience. While scientists certainly seek theories that have a high degree of empirical corroboration, as the philosopher Karl Popper noted, ‘we do not seek highly probable theories but explanations; that is to say, powerful and highly improbable theories.’ ” [19]
Chomsky criticizes machine learning for its exclusive focus on prediction rather than developing theories and explanations. In the article, he is particularly doubtful that current large language models provide deep insight into human language.
1.6 Machine learning can be more than a tool
We share these critical views above to a certain degree. Machine learning algorithms have problems with being dumb curve-fitters that lack causality. Purely predictive models might make bad explanatory models. And machine learning doesn’t produce scientific theories as we are used to.
Nevertheless, there are reasons for optimism that these issues can be addressed and that machine learning can play a big role in science. The roles we see machine learning play were already shining through some of the initial examples:
- Inform actions: Tornado forecasting is not just an intellectual forecasting exercise, but is crucial for taking the right measures to prevent harm.
- Gain insights: In the case of almond yield prediction, the goal wasn’t only to build a prediction machine, but the researchers also extracted insights from the model.
- Exploration: AlphaFold isn’t a mere proof of concept. For example, protein structure predictions are used by researchers to explore and test new drugs.
However, machine learning cannot fulfill these roles in its raw form. It must be equipped with “upgrades” such as (causal) domain knowledge, interpretability, uncertainty, and so on, to become a new approach for informing peoples’ actions, extracting insights from data, or generating new hypotheses. We believe that fully upgraded supervised machine learning models have the potential to become a full-blown scientific methodology that helps scientists to better understand phenomena.
The upgrades we need are readily available. Every year, new sub-fields are emerging. If we think of machine learning not in isolation, but in conjunction with these upgrades, machine learning could provide great scientific value. Like a puzzle, we have to piece all of it together, starting with a justification of why a machine learning approach focused on prediction is a good core idea for research.
But before we can justify machine learning or start solving the puzzle, let’s look at supervised machine learning in its raw form!
Technically, they are legumes, but we’re not biologists and we eat them as if they were nuts.↩︎